昨天介紹 data pipeline 的管理工具,今天讓我們邁入下一步,先來介紹資料版本要如何控管,接著介紹在建立機器學習模型時,要如何有效率地進行實驗追蹤和視覺化吧。
DVC(Data Version Control)是一個開源的版本控制系統,專門用於管理和追蹤機器學習專案中的數據和模型。簡單來說,DVC 就是 data 版本的 Git,將版本控制的概念引入機器學系專案中,讓我們可以更有效率地追蹤和共享每一個版本的資料集和模型。
接下來介紹 DVC 的基本使用方法。
安裝 DVC:pip install dvc
在 Git 目錄中初始化DVC
dvc init
git commit -m "Initialize DVC"
dvc add data.csv
git add data.csv.dvc .gitignore
git commit -m "Add data.csv to DVC"
dvc add data.csv 指定會讓 DVC 將文件的資訊儲存在 .dvc 檔案中,並且原本的 data.csv 移到 cache。
dvc remote add -d myremote s3://mybucket/dvcstore
git commit .dvc/config -m "Configure remote storage"
dvc push
DVC 也可以用來建立 data pipelines,建立方法可以使用 dvc stage add 來建立每個 stage 的內容,也可以建立一個 dvc.yaml 來定義 data pipeline。
dvc stage add以下是一個示範的指令。
dvc stage add -n prepare \
-p prepare.seed,prepare.split \
-d src/prepare.py -d data/data.xml \
-o data/prepared \
python src/prepare.py data/data.xml
以上定義這個 stage 的幾個資訊:
-n prepare:使用 -n 來為這個 stage 命名,如 prepare 是該 stage 的名稱。
-p prepare.seed,prepare.split:-p 用來指定這個 stage 中會使用到的參數,參數數值會在 params.yaml 中被指定的參數,讓 DVC 可以追蹤這些參數的變化,並確保每次運行都可以重現結果。
-d src/prepare.py -d data/data.xml:-d 代表 dependencies(依賴),DVC 會追蹤這些 dependencies 的變化,若任一個 dependencies 改變,DVC 會重新運行這個 stage。此處有兩個 dependencies:
-o data/prepared:-o 代表 output(輸出),指定輸出的目錄或文件,此處是 data/prepared。
DVC 會追蹤這個輸出目錄中的內容,並將其作為該 stage 的結果。如果輸出文件發生變化,DVC 會更新相關版本。
python src/prepare.py data/data.xml:這是實際執行的命令。DVC 會執行 src/prepare.py,並使用 data/data.xml 作為輸入文件。
整體來說,這個 stage 會執行 src/prepare.py,用以處理輸入數據(data/data.xml),並生成處理後的數據文件到 data/prepared 目錄。
使用 dvc stage add 的話,會自動生成 dvc.yaml,也可以直接編輯 dvc.yaml 來定義 data pipeline:
stages:
prepare:
cmd: python src/prepare.py data/data.xml
deps:
- src/prepare.py
- data/data.xml
params:
- prepare.seed
- prepare.split
outs:
- data/prepared
featurize:
cmd: python src/featurization.py data/prepared data/features
deps:
- src/featurization.py
- data/prepared
params:
- featurize.max_features
- featurize.ngrams
outs:
- data/features
train:
cmd: python src/train.py data/features model.pkl
deps:
- src/train.py
- data/features
params:
- train.seed
- train.n_est
- train.min_split
outs:
- model.pkl
以上的程式碼中,我們定義了三個 stages:prepare、featurize 和 train,接著,可以使用 dvc repro 來執行 pipeline,也可以使用 dvc dag 來查看 pipeline 的 DAG,如以下所示:
+---------+
| prepare |
+---------+
*
*
*
+-----------+
| featurize |
+-----------+
*
*
*
+-------+
| train |
+-------+
以上是 DVC 管理資料版本和建立 data pipeline 的方式。
不過 DVC 的功能還不只這樣哦,接下來讓我們看一下他要怎麼追蹤實驗跟管理模型。
如果想要用 DVC 管理實驗數據,需要先使用 pip install dvclive 來安裝 DVCLive。
使用的方式非常簡單,假設你使用 hugging face 的話,只要在如以下示範增加幾行程式碼,即可開始追蹤數據。他也支援 Pytorch、Keras 或是單純使用 Python 呼叫。
from dvclive import Live
from dvclive.huggingface import DVCLiveCallback
...
with Live() as live:
trainer.add_callback(
DVCLiveCallback(live=live)
)
trainer.train()
trainer.save_model("mymodel")
live.log_artifact("mymodel", type="model")
每次執行程式碼都會創建一個 DVC 實驗,DVCLive 會自動記錄一些來自機器學習框架的 metrics、parameters 和圖表,以及由 DVC 追蹤的任何數據。我們也可以自行定義要繼續哪些其他資訊,如以下所示:
live.log_artifact("model.pt", type="model", name="gpt")
live.log_image("image.png", img)
live.log_metric("acc", 0.9)
live.log_params(params)
live.log_plot( "iris", datapoints, x="importance", y="name", template="bar_horizontal", title="Iris Feature Importance" )
live.log_sklearn_plot("roc", y_true, y_score)
接著,我們可以使用 DVCLive 的 report 來追蹤這些數據。
有三個以下方法:



如果在上述內容中,使用 live.log_artifact(),DVC 會將模型加入 model registry。如此一來,便可以透過 DVC 追蹤和管理模型。
若我們執行以下程式碼:
from dvclive import Live
with Live() as live:
...
live.log_artifact(
str("models/model.pkl"),
type="model",
name="pool-segmentation",
desc="This is a Computer Vision (CV) model that's segmenting out swimming pools from satellite images.",
labels=["cv", "segmentation", "satellite-images", params.train.arch],
)
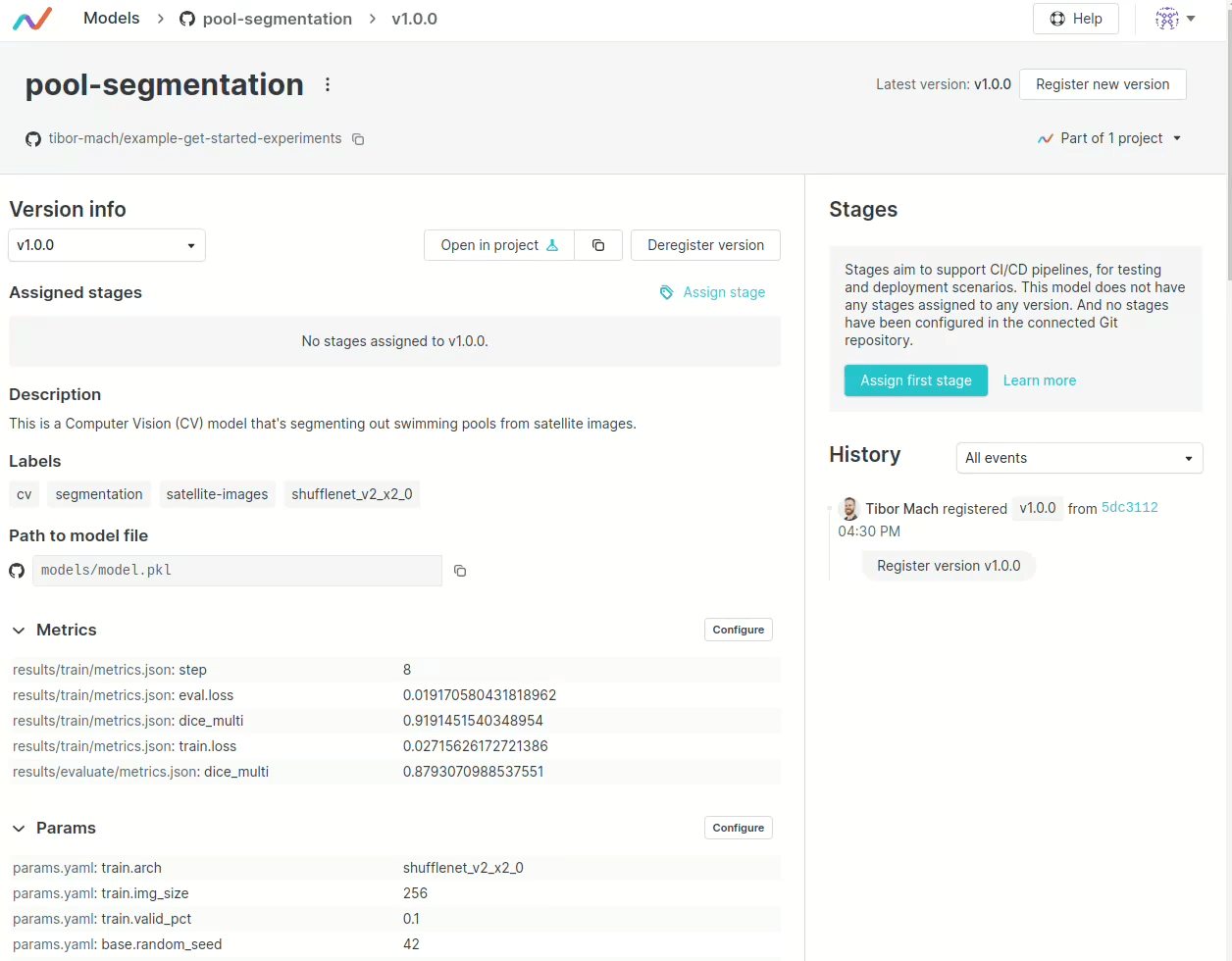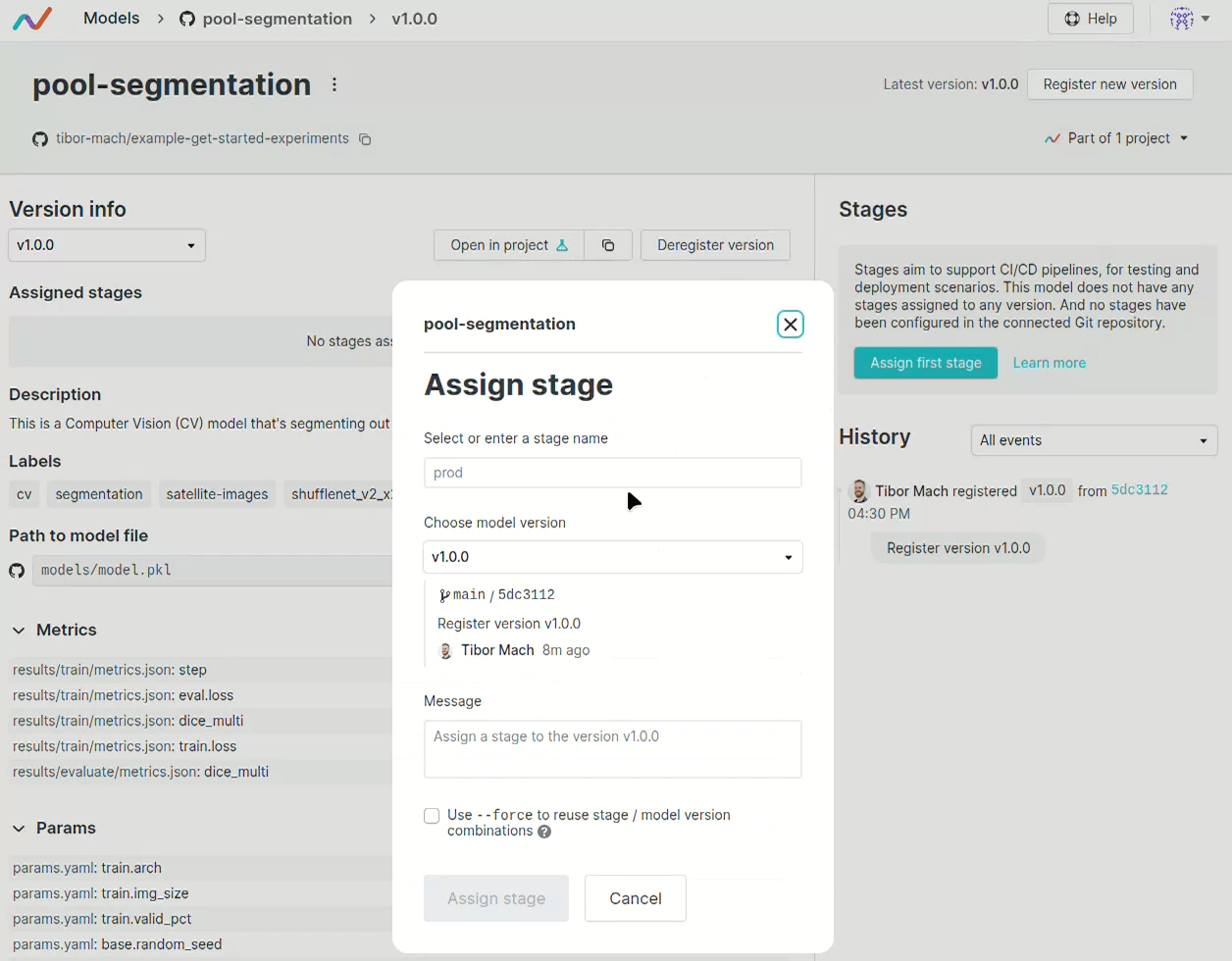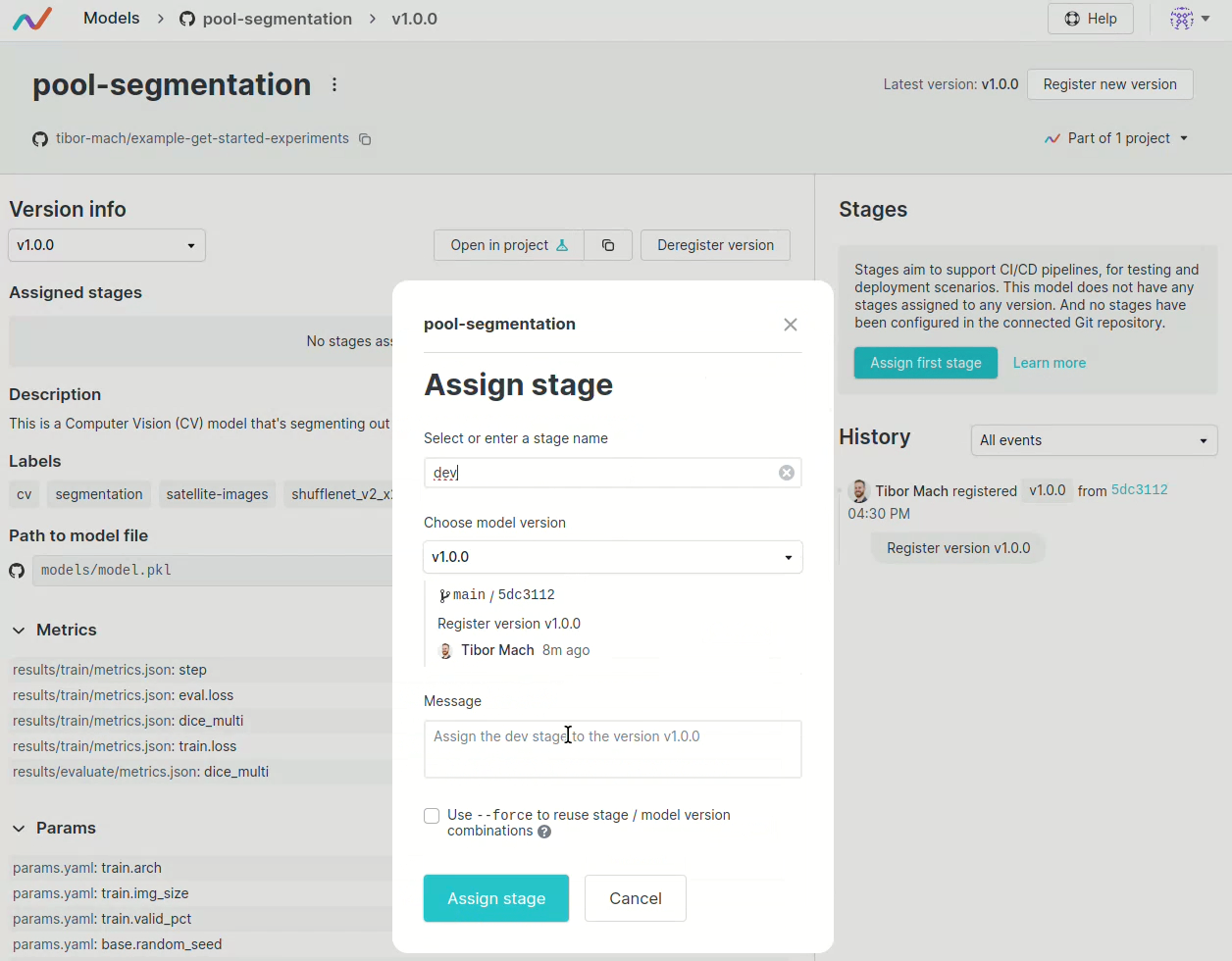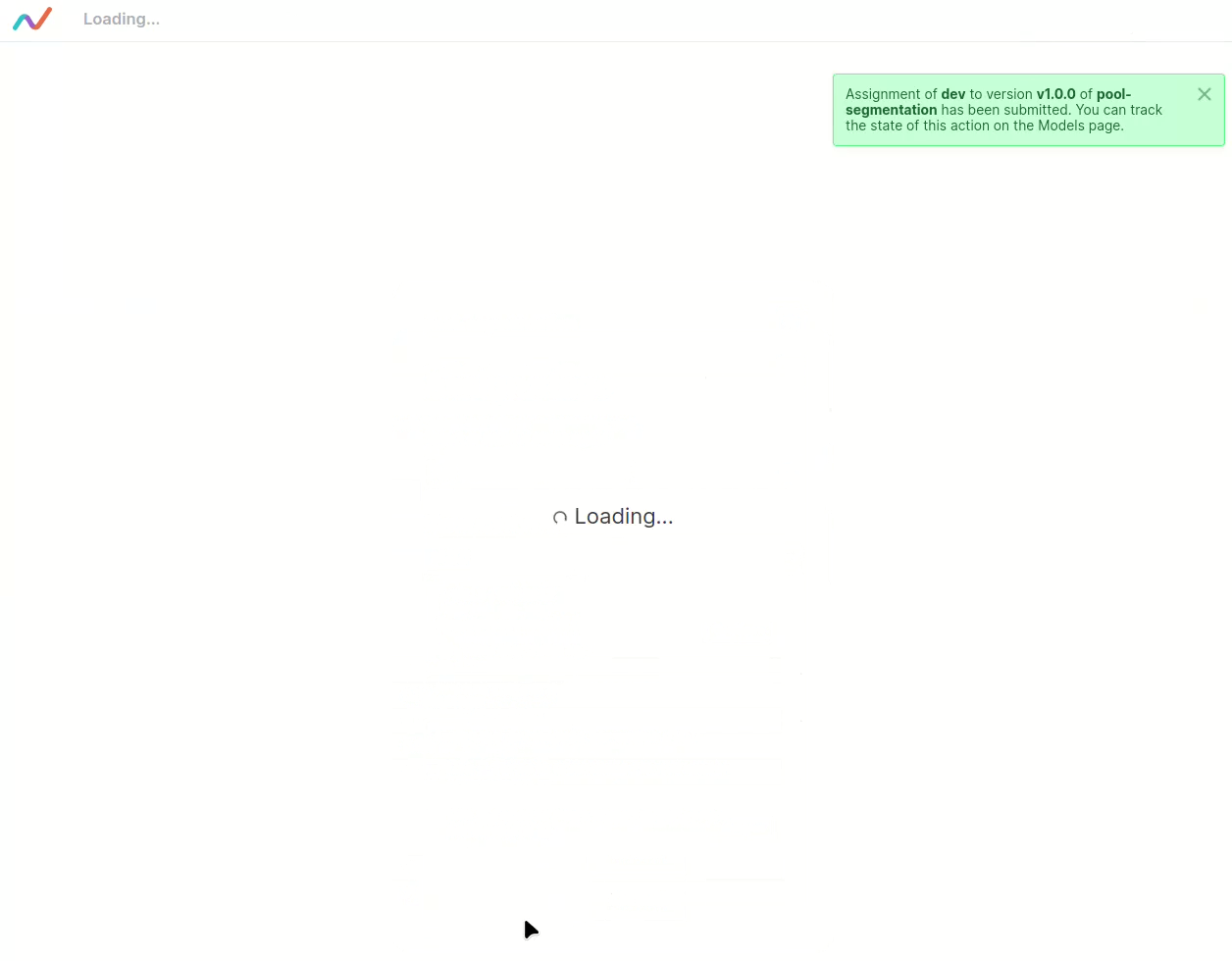
便可以在 DVC Studio 的 Models 頁面,看到名為 pool-segmentation 的模型,以及他的描述。
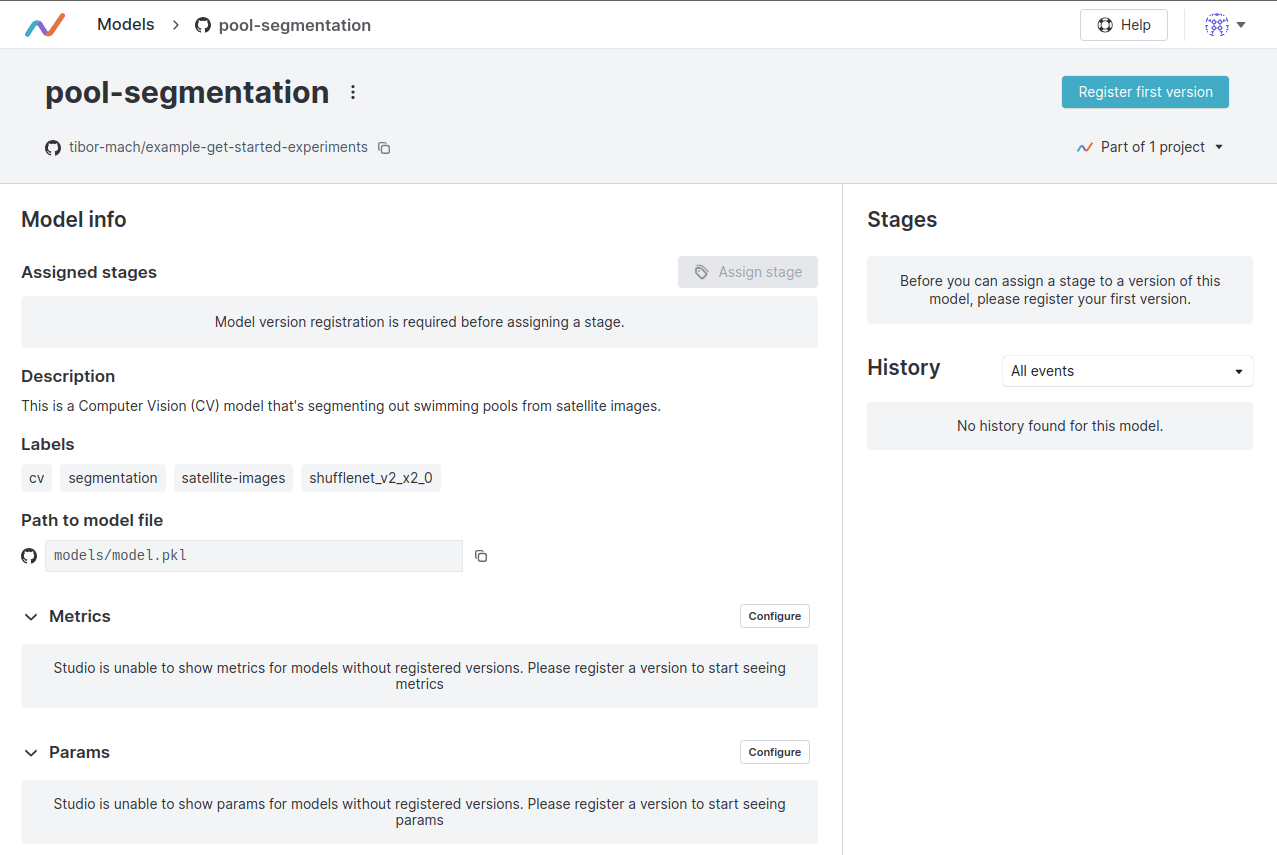
我們可以方便地用 UI 進行模型的版本設定。
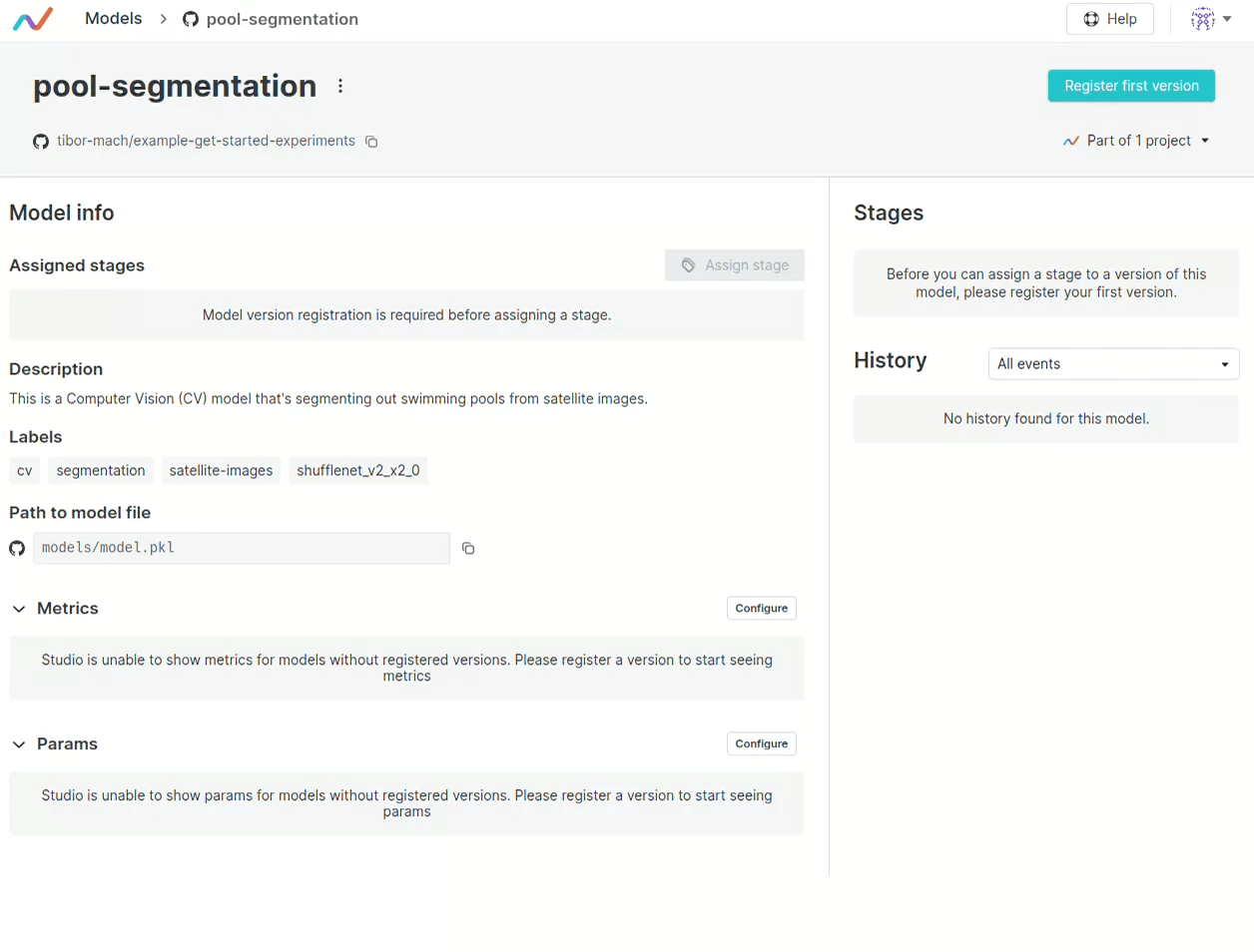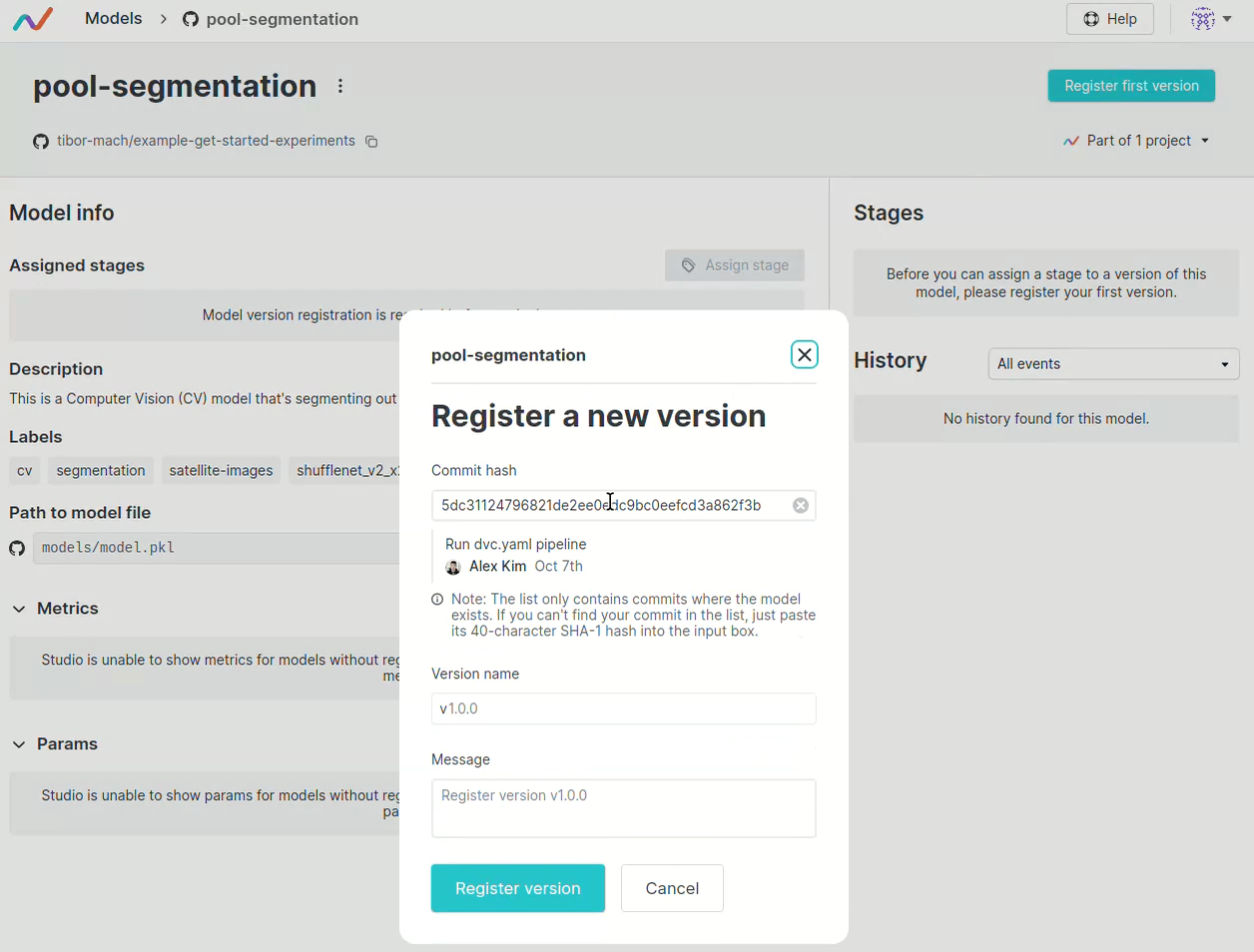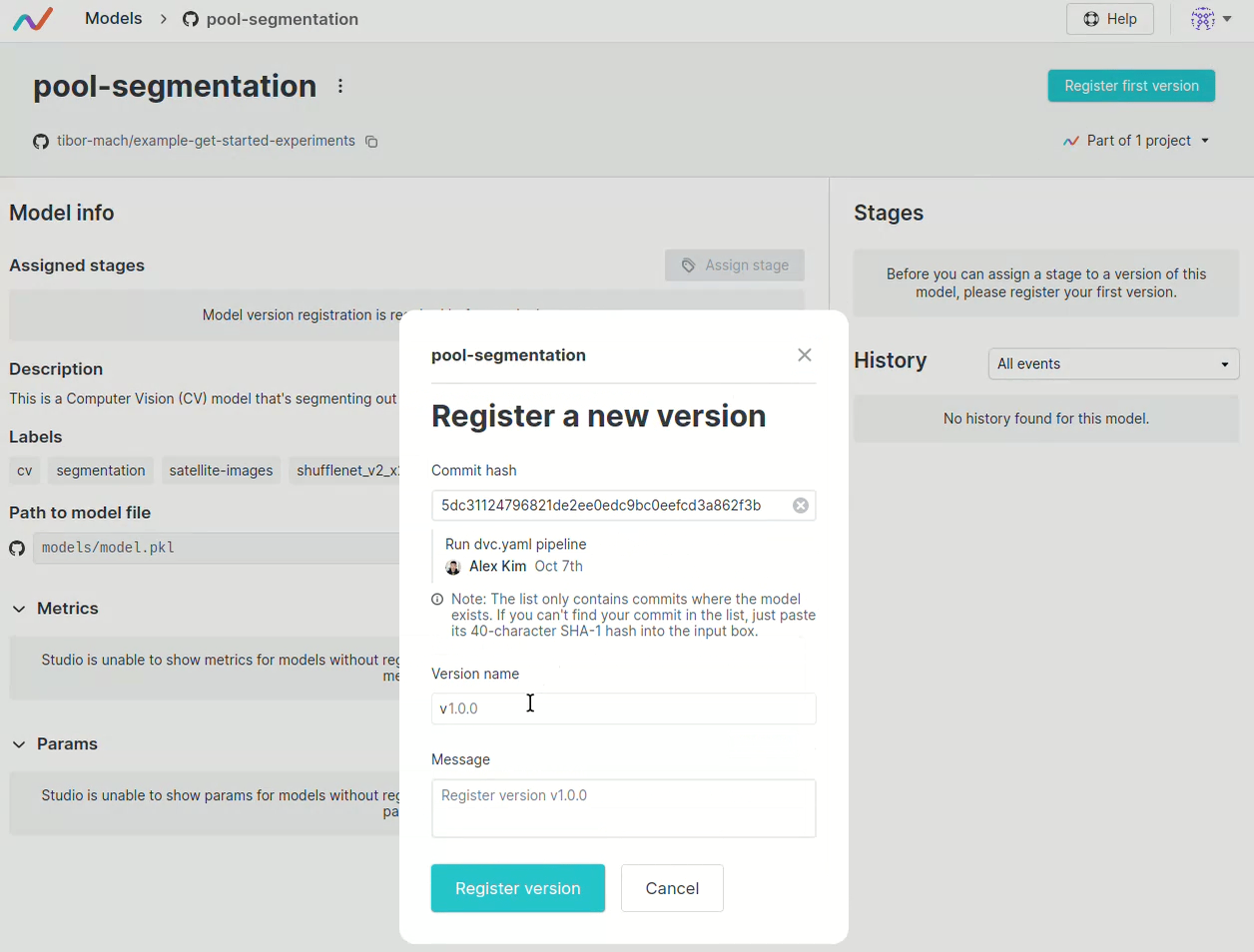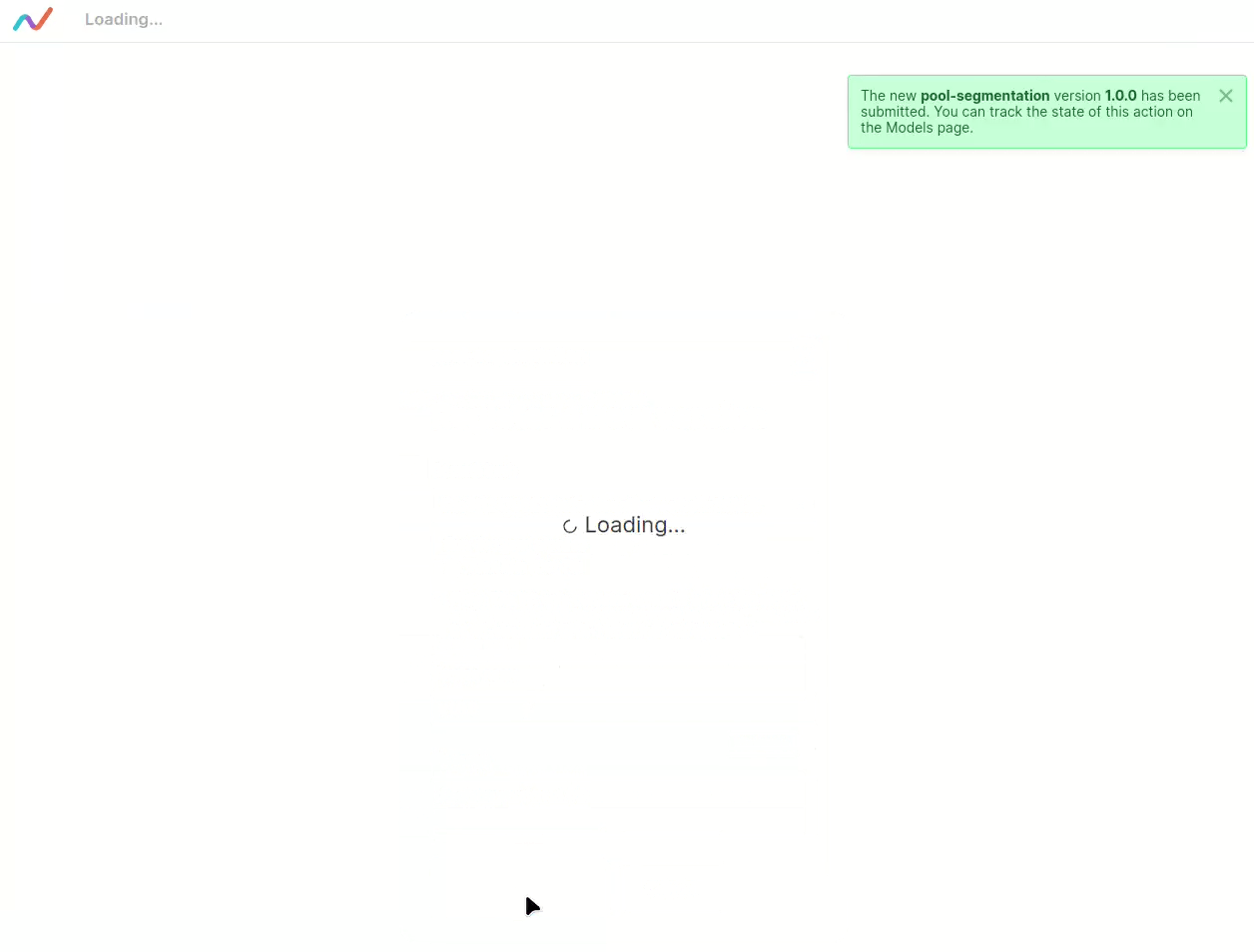
也可以設定模型的部署環境,並且會自動觸發 CI/CD,將模型部署到指定的環境。
我們在本篇文章中大致介紹了 DVC 的功能,他有非常強大的版本控制和實驗管理能力,讓我們可以更好地協作、追蹤實驗、管理資料集,並確保結果的可重現性。
如果我們不需要建立複雜的 data pipelines,也可以考慮先從 DVC 開始,輕量又好上手!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference:
[1] https://dvc.org/doc/start
[2] https://dvc.org/doc/start/experiments/experiment-tracking?tab=DVCLive-Report

